Analiza danych to proces przetwarzania danych w celu uzyskania na ich podstawie użytecznych informacji i wniosków. Paul Hague określa ten proces jako kumulowanie pojedynczych odpowiedzi lub „surowych danych”[1].
W celu przygotowania wyników badania konieczna jest właściwa organizacja czynności, które poprzedzają interpretację, czyli uporządkowanie zebranych informacji i ich analiza pod kątem sformułowanych wcześniej celów badania. Dane uzyskane z pomiarów, głównie pierwotnych nie nadają się do bezpośredniego stosowania. Zanim będzie można z nich skorzystać, muszą zostać zredukowane, a następnie zanalizowane i zinterpretowane za pomocą odpowiednich metod. Procesy te można znacznie skrócić stosując odpowiednie programy komputerowe.
Poszczególne etapy przygotowania danych do dalszej pracy możemy podzielić na kolejne procesy[2]:
- Redagowanie danych
- Kodowanie
- Tabulacja
Redagowanie, czyli początkowy etap „obróbki” wyników polega na narzuceniu pewnych minimalnych standardów jakościowych surowym danym[3]. Należy w tym miejscu zredukować nadmiar materiałów, wyłapać dane zbędne oraz uporządkować te potrzebne. Należy sprawdzić, czy kwestionariusz jest kompletny, czy zachowano kolejność odpowiadania na pytania (w przypadku konieczności pomijania pewnych pytań) oraz czy odpowiedzi nie są ze sobą sprzeczne (np. jeśli respondent zaznaczył, że chodzi do pracy pieszo, to czy można uwierzyć w to, że w jedną stronę pokonuje odległość 30 km?). Prace edytorskie mogą zostać wykonane jedynie przez osoby odpowiednio do tego przeszkolone.
Po zakończeniu eliminacji i porządkowania, dane są klasyfikowane i kodowane. Pierwszym krokiem jest określenie kategorii lub klas, w których umieszczone zostaną odpowiedzi. Kodowanie pytań zamkniętych w większości jest proste, gdyż ustala się je już na etapie projektowania arkusza. Sprawa się komplikuje podczas kodowania pytań otwartych. Kodujący musi określić stosowne kategorie i przedziały na podstawie zebranych odpowiedzi.
Drugi krok w etapie kodowania polega na przypisaniu klasom numerów kodowych. W przypadku płci mogą to być M na oznaczenie mężczyzn i K dla oznaczenia kobiet. Jednakże, do oznaczenia kategorii lepiej stosować liczby niż litery. Jeżeli kodowanie przeprowadzamy za pomocą komputera niezbędne jest takie zakodowanie danych, by mogły być bez trudu do niego wprowadzane[4]:
- Ważne jest, aby używać tylko jednego oznaczenia na kolumnę (komputer może nie odczytać wielu znaków);
- Używać tylko kodów liczbowych, a nie liter alfabetu;
- Wyniki powinny być zapisane z użyciem tylu kolumn, ile jest wariantów zmiennej;
- Używać standardowego kodu na oznaczenie „braku informacji”;
- Kodować na każdym rejestrze numer identyfikacyjny respondenta.
Ostatnim elementem kodowania jest przygotowanie książki kodowej. Zawiera ona instrukcje, które wskazują, jak zakodowano poszczególne dane. Oblicza kody dla każdej zmiennej i kategorie objęte poszczególnymi kodami. Wskazuje też lokalizację zmiennej w zapisie komputerowym oraz sposób odczytywania zmiennych.
Ostatni etap obróbki danych to tabulacja. Jest to nic innego jak zliczanie poszczególnych odpowiedzi. Jest to proces pracochłonny, jednakże niezastąpiony w analizie wyników badań. W tym procesie sumuje się ilość występowania danego wariantu zmiennej. Jeżeli dane uzyskane z odpowiedzi na jedno pytanie są uszeregowane w formie tablicy, to jest to tabulacja prosta. Jeżeli dane z odpowiedzi na dwa lub więcej pytań szereguje się w jednej tablicy, to otrzymujemy jednocześnie dwa lub więcej rozkładów, tworzących tablicę złożoną[5].
- Tabulacja prosta
Podstawowy warunkiem jest występowanie tylko jednej zmiennej. Najczęściej stosuje się tu szeregi statystyczne czasowe i przestrzenne. Użytecznym środkiem przedstawiania wyników badania są tabulogramy proste. Służą jako podstawowe źródło danych do obliczania takich miar jak mediana, średnia, odchylenie standardowe. Poniżej znajduje się przykład tabulacji prostej. Tabela przedstawia jedną zmienną – liczbę samochodów na rodzinę.
Tabela 1. Samochody na rodzinę (tabela częstości)
|
Liczba samochodów na rodzinę
|
Liczba rodzin
|
Odsetek rodzin
|
|
1
2
3
|
75
23
2
|
75,00
23,00
2,00
|
|
Razem
|
100
|
100,00
|
Źródło: http://www.mrpro.pl/download/Badania_podrecznik_1.pdf, stan na dzień 21.12.2011.
- Tabulacja złożona
Tabele budowane są na podstawie odpowiedniej kombinacji cech korelowanych (zestawianych) ze sobą. Jeśli korelowane są ze sobą 2 cechy, to mamy tabele dwudzielcze. Podstawowym warunkiem jest występowanie co najmniej dwóch zmiennych. Populacja złożona jest najważniejszym narzędziem studiowania związków między zmiennymi. Próba jest dzielona na podgrupy w celu poznania sposoby zmienności zmiennej zależnej dla każdej podgrupy. Tabulogramy złożone są użytecznym narzędziem studiowania zależności pomiędzy zmiennymi, gdyż ułatwiają komunikowanie wyników. Umożliwiają również wgląd w charakter tych zależności.
Tabela 2. Opinie o produkcie x (tabela dwudzielcza)
|
Zakupy produktu x
|
Opinie o produkcie x
| ||
|
negatywne
|
pozytywne
|
suma
| |
|
Częste
Rzadkie
|
30
70
|
75
25
|
105
95
|
|
suma
|
100
|
100
|
200
|
Źródło: http://www.mrpro.pl/donload/Badania_podrecznik_1.pdf, stan na dzień 21.12.2011.
Na podstawie tej tabeli można obliczyć odpowiednie proporcje obserwacji względem sum w każdym wierszu, w każdej kolumnie lub w stosunku do wszystkich obserwacji.
Po odpowiednim stworzeniu takiej bazy danych, która zawiera uzyskany materiał, następuje etap wyjaśnienia danych, najlepiej w oparciu o wytłumaczenie własnych reakcji przez respondentów. Przy interpretacji uwzględnia się częstotliwość, z jaką pojawia się dana myśl oraz kolejność wyrażania poszczególnych opinii.
W literaturze można odnaleźć wiele metod analizy danych. Dietmar Pfaff wyróżnia trzy poniższe metody[6]:
1. Metoda jednowymiarowa, polegająca na obserwacji jednej zmiennej lub jej cechy.
2. Metoda dwuwymiarowa, badająca relacje między dwoma zmiennymi.
3. Metoda wielowymiarowa, będąca analizą co najmniej trzech zmiennych podlegających jednoczesnej obserwacji.
Analiza jednowymiarowa jest prosta i stanowi punkt wyjścia do dalszych analiz, ponieważ dzięki niej możliwy jest wgląd w problem badawczy. Do tej metody zalicza się rozkład częstości (tzw. liczenie ludzi, polega na regularnym badaniu i prezentacji częstości cechy) oraz opisujące go parametry położenia (np. wartość średnia) i rozrzutu (np. odchylenie standardowe). Analiza jednowymiarowa jest najprostszym przypadkiem w analizie statystycznej, polega na użyciu zebranych danych dotyczących jednej próby i wyciągnięciu interesujących nas wniosków.
W oparciu o rozkłady częstości można zaobserwować zmiany zachodzące w konkretnym okresie oraz podjąć stosowne działania. Uporządkowana baza danych pozwala sporządzić histogramy – wykresy kołowe, słupkowe, belkowe, które lepiej przedstawią wybrane zagadnienia.
Wartość średnia jest jednym ze sposobów ustalania uśrednionych wartości, czyli opisywania rozmieszczenia poszczególnych wartości za pomocą jednej zmiennej. W procesie interpretacji danych bardzo ważne jest jednak także to, by rozważyć stopień ich rozproszenia wokół średniej. Wskaźnikiem najczęściej wykorzystywanym w tym celu jest standardowe odchylenie – jest to element umożliwiający dokonanie oceny rozproszenia danych zebranych w ramach populacji, z której dobrana została próba, czyli obliczenia błędu standardowego, na którego podstawie można następnie oszacować margines błędu lub sprawdzić różnicę między dwoma wynikami pod kątem jej rzeczywistego znaczenia statystycznego[7].
Analizę dwuwymiarową stosuje się na wszystkich poziomach pomiaru. Służy do opisu zależności, które zachodzą pomiędzy dwoma obserwowanymi zmiennymi. Wśród relacji wyróżniamy korelację i asocjację. Ponadto, do metod dwuwymiarowych należą: analiza tabel krzyżowych, prosta analiza korelacji i regresji oraz porównanie wartości średnich.
Najprostszym przedstawicielem tej analizy jest tabela krzyżowa, którą można stosować niezależnie od przyjętej skali. Rozkład kategorii jednej zmiennej prezentowany jest ze względu na rozkład kategorii drugiej zmiennej. Poniższa tabela jest przykładem tabeli krzyżowej. Rozkład miejsca zamieszkania prezentowany jest ze względu na rozkład kierunku studiów.
| | |
| |  |
Źródło: http://www.racjonalista.pl/kk.php/s,5492, stan na dzień 21.12.2011.
Na wstępie analizy, należy podzielić zmienne na grupy, np. grupy studentów medycyny i prawa. Następnie do dwuwymiarowej tabeli krzyżowej trzeba nanieść wszelkie możliwe kombinacje cech. W prezentowanym przykładzie dotyczącym rozproszenia studentów prawa i medycyny te cechy są wielkościami miejscowości. Segmentacja według cech społeczno – demograficznych daje możliwość dokładnej charakterystyki tych grup na podstawie wyodrębnionych między nimi różnic i pozwala rozpoznać zależności oraz sprzeczności w odpowiedziach niejednorodnie dobranych grup respondentów.
Analizy tego typu są najczęściej spotykane w konsumenckich badaniach rynkowych. Analiza krzyżowa może zostać przeprowadzona na podstawie odpowiedzi na dowolne z pytań zawartych w kwestionariuszu, ale nie może być jednak mowy o dokonywaniu klasyfikacji danych według kryterium nieporuszonego w ankiecie lub według prawdopodobnych odpowiedzi na pytanie, które zostało respondentom zadane. W związku z tym warto pamiętać, że planowanie analizy danych należy rozpocząć już na etapie projektowania kwestionariusza.
Jeśli chodzi o analizę wielowymiarową, jednoczesnej obserwacji podlegają co najmniej trzy zmienne. Do metod wielowymiarowych, które służą określeniu struktur powiązań między obiektem a zmiennymi, należą analiza skupień i analiza czynnikowa.
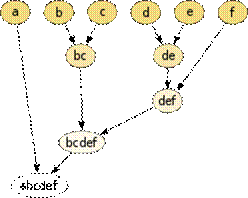
Analiza skupień polega na znajdowaniu podobieństw i różnic obserwowanych obiektów. Grupuje się je w miarę jednorodne klasy, w taki sposób, by każdy element był bardziej podobny do elementów należących do grupy niż tych spoza niej, tworząc grupy homogeniczne. Następnie tworzy się dendogram, który ukazuje podobieństwo i różnice pomiędzy wybranymi elementami.
| | |
| |  |
Źródło: http://www.mathworks.com/help/toolbox/stats/dendrogram.html, stan na dzień 20.12.2011.
Na powyższym schemacie widać, iż obiekty „b” i „c” są najbardziej do siebie podobne, zaznaczone jest więc między nimi połączenie. Podobnie sprawa wygląda w przypadku obiektów „d” i „e”. Następnie dopiero grupa „de” oraz obiekt „f” są do siebie stosunkowo podobne, dlatego dochodzi do „połączenia” i utworzenia grupy „def”. Analogicznie schemat tworzony jest do końca.
Analiza czynnikowa służy kompresji lub redukcji objętości danych. Nie dochodzi przy tym do dużych strat informacji. Ta metoda zakłada, że zmienne niezależne często się uzupełniają albo wyrażają tę samą lub podobną treść. Empiryczne wartości zmiennych redukuje się do najważniejszych, między którymi liczy się korelację. Potem na ich podstawie wyodrębnia się określone czynniki.
Przy statystycznym pomiarze danych z reguły występują czynniki lub błędy, które mogą mieć negatywny wpływ na wyniki. Są wyrażone za pomocą odchyleń otrzymanych danych pomiarowych od rzeczywistych wartości[8]:
- Błędy przypadkowe – oscylują wokół wartości rzeczywistej, tak że ostatecznie się wyrównują. Liczbę tego typu błędów można zmniejszyć za pomocą zwiększenia zakresu próby.
- Błędy systematyczne – pojawiają się na wszystkich etapach zbierania danych. Nie rozkładają się równomiernie wokół rzeczywistej wartości średniej, lecz koncentrują się na pewnym określonym kierunku.
Przyczynami powstawania błędów systematycznych mogą być błędy prowadzących badania, np. użycie błędnych dokumentów; błędy ankieterów, np. zastosowanie błędnych metod doboru próby lub sugestywne formułowanie pytań; oraz błędy respondentów, np. udzielenie błędnych odpowiedzi lub brak odpowiedzi. Kontrola pomiaru, doświadczenie i rozwaga mają pozytywny wpływ na redukcję błędów systematycznych.
Reasumując, kiedy dane są już zebrane, przystępujemy do analizy, która oznacza określenie znaczenia zebranych informacji. Aby rozpocząć interpretację posiadanych informacji, należy je wyselekcjonować i poukładać; zredagować. Dopiero wtedy możemy przejść do szczegółowej analizy tych danych. Celem analiz wieloczynnikowych (podobnie zresztą, jak wszystkich pozostałych) jest wskazanie cech najbardziej charakterystycznych dla danego rynku oraz wzajemnych zależnościach między nimi. Innymi słowy, analizowanie danych jest formą tworzenia modeli statystycznych, które pomagają zrozumieć zasady funkcjonowanie rynku. Można je także wykorzystywać do przewidywania skutków podejmowanych działań marketingowych – chodzi tu po prostu, by zadać sobie pytanie „co by było, gdyby…?”. Na koniec chcielibyśmy zaznaczyć, że nie zawsze jest tak, że najbardziej złożona analiza okazuje się najlepsza. Bardzo często prosta analiza krzyżowa pozwoli uzyskać wystarczająco dobre wyniki, które mogą być bez problemu wykorzystywane przez osoby podejmujące decyzje biznesowe.
4. Bibliografia
- Churchill G. A., Badania marketingowe. Podstawy metodologiczne., Wydawnictwo Naukowe PWN, Warszawa 2002;
- Hague P., Badania marketingowe. Planowanie, metodologia i ocena wyników., Wydawnictwo HELION, Gliwice 2006;
- Kaczmarczyk S., Badania marketingowe. Metody i techniki., Polskie Wydawnictwo Ekonomiczne, Warszawa 2003;
- Nikodemska – Wołowik A. M., Klucz do zrozumienia nabywcy – jakościowe badania marketingowe., Wydawnictwo GrupaVerde, Warszawa 2008;
- Pfaff D., Badania rynku. Jak pozyskać najistotniejsze dla firmy informacje marketingowe., Wydawnictwo BC.edu, Warszawa 2010.
[1] P. Hague, Badania marketingowe. Planowanie, metodologia i ocena wyników., Wydawnictwo HELION, Gliwice 2006, s.257.
[2] G. A. Churchill, Badania marketingowe. Podstawy metodologiczne., Wydawnictwo Naukowe PWN, Warszawa 2002., s. 612
[3]Ibidem.
[4]Ibidem.
[5] S. Kaczmarczyk, Badania marketingowe. Metody i techniki., Polskie Wydawnictwo Ekonomiczne, Warszawa 2003, s. 261 – 262.
[6] D. Pfaff, Badania rynku. Jak pozyskać najistotniejsze dla firmy informacje marketingowe., Wydawnictwo BC.edu, Warszawa 2010, s.96.
[7] P. Hague, Badania marketingowe… op.cit.
[8] D. Pfaff, Badania rynku… op. cit.

kontrat
Użytkownik
Punkty rankingowe:
Zdobyte odznaki:
0kontrat
Użytkownik