
Spis treści:
- Czym jest model językowy?
- Na czym polega uczenie modelu językowego?
- Czy model językowy "rozumie, co mówi"? Argument "chińskiego pokoju"
Czym jest model językowy?
Z pewnością czym wyjątkowym.
Najlepiej dowodzi tego fakt, że model językowy sam może powiedzieć nam, czym jest. Taką definicję zaproponował najbardziej znany z takich modeli – ChatGPT:
"Duży model językowy to rodzaj programu komputerowego, który uczy się zasad języka, takiego jak gramatyka i znaczenie słów. Potrafi przewidywać, jakie słowa lub zdania mogą wystąpić po innych słowach. Dzięki temu może generować sensowne teksty, pomagać w tłumaczeniach oraz lepiej zrozumieć to, co ludzie piszą lub mówią."
Wszyscy mówią jednak, że takim programom nie wolno "wierzyć na słowo", bo potrafią podawać błędne informacje. Sprawdźmy więc inną definicję, na przykład w kompendium wiedzy na stronie IBM. Tam dowiadujemy się, że:
"Duże modele językowe (ang. Large Language Model, LLM) to kategoria modeli fundamentalnych, które są szkolone na ogromnych ilościach danych, dzięki czemu są w stanie rozumieć i generować język naturalny i inne rodzaje treści w celu wykonywania szerokiego zakresu zadań."
Wygląda na to, że w tym przypadku model językowy poradził sobie całkiem dobrze. Powiem więcej, poradził sobie lepiej niż autor drugiego cytatu. Po pierwsze, stworzył definicję, która do zrozumienia istoty zagadnienia nie wymaga znajomości innych terminów takich jak "model fundamentalny".
Po drugie, zdecydowanie ważniejsze – w tekście wygenerowanym przez sztuczną inteligencję nie pojawia się słowo "rozumieć". Mowa jest tylko o "przewidywaniu" kolejnych słów, co po tysiąckroć lepiej opisuje zasadę działania modeli językowych.
Na czym polega uczenie modelu językowego?
Jeżeli model się "uczy" to chyba znaczy, że nabywa nową wiedzę – zaczyna ją "rozumieć". Wydaje się, że jednak nie do końca. Zanim spróbujemy wyjaśnić tę kwestię, musimy nieco lepiej zrozumieć, jakie mechanizmy stoją za możliwościami, które oferują coraz lepsze modele językowe. Przy okazji ustalimy też, co pozwala na poprawę ich osiągów i czy proces może trwać w nieskończoność, aż w pewnym momencie model przewyższy zdolności językowe człowieka.
Modele językowe wykorzystują algorytmy uczenia głębokiego (deep learning). Uczenie głębokie to z kolei podkategoria uczenia maszynowego, która zaprzęga do działania sztuczne sieci neuronowe (SSN) składające się z co najmniej trzech warstw, choć w przypadku obecnych modeli językowych jest ich znacznie więcej.
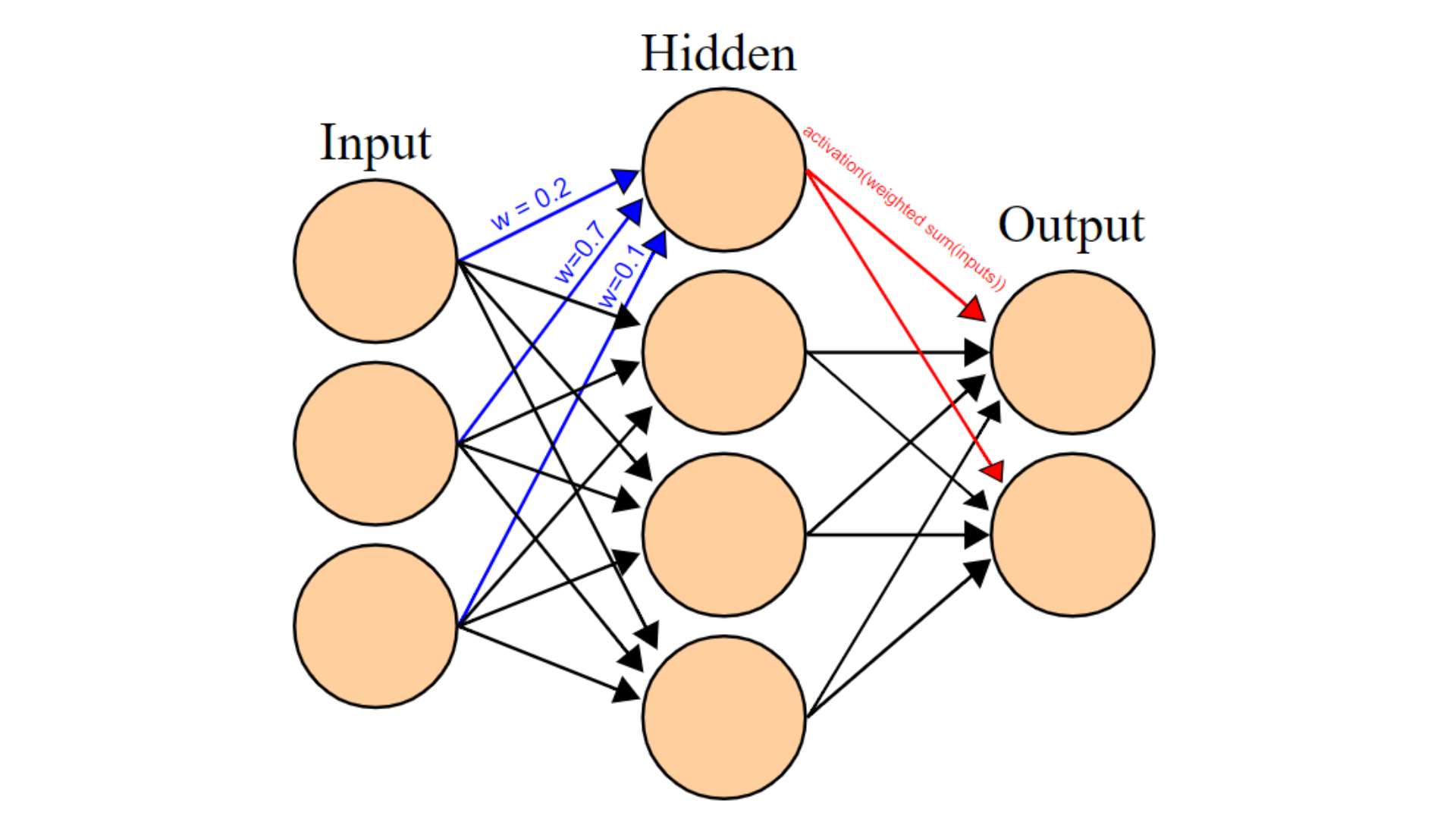
W ludzkim mózgu, żeby pobudzony neuron "uruchomił" kolejne komórki nerwowe, siła sygnału musi przekroczyć pewien próg aktywacji. W sztucznych sieciach neuronowych proces ten imitują wagi przypisywane połączeniom między "neuronami" na kolejnych warstwach. Algorytm SSN sam dostosowuje później wartości wag tak, aby uzyskać maksymalnie satysfakcjonującą odpowiedź. Skąd jednak model wie, jak wygląda "ideał", do którego powinien się zbliżać? Do tego potrzebny jest nauczyciel – w tym przypadku człowiek.
Sprawdź też: Bot, robot, awatar… Czym się różnią i co oznaczają te terminy?
Zanim jednak dotrzemy do tego etapu, sieciom prezentuje się ogromne zbiory danych tekstowych w języku naturalnym (w przypadku GPT-3 było to łącznie 45 TB tekstu). Na tej podstawie algorytm uczy się rozpoznawać wzorce i zależności między słowami – kluczową kwestią jest statystyczna szansa wystąpienia jakiegoś słowa w danym miejscu tekstu. Model stara się odgadnąć, jakie słowa lub zdania są bardziej prawdopodobne w danym kontekście, ucząc się na podstawie częstotliwości występowania różnych kombinacji słów w zbiorze treningowym.
W następnej fazie treningu odpowiedzi generowane przez model są sprawdzane i poprawiane przez oddelegowanych pracowników, a model na podstawie wskazówek aktualizuje wagi poszczególnych połączeń tak, aby jego przewidywania dotyczące kolejnych słów były coraz bardziej adekwatne.
Co stoi za sukcesem tak skonstruowanych modeli i ciągłej poprawie ich wyników? No cóż, trudno mówić tu o wybitnej finezji zastosowanego rozwiązania. Wzrost możliwości obliczeniowych pozwala na wykorzystywanie do treningu coraz większej ilości danych i coraz większej liczby parametrów (połączeń między poszczególnymi neuronami w sieci). Mamy tu więc do czynienia z dość topornym, ilościowym rozwiązaniem.
Czy model językowy "rozumie, co mówi"? Argument chińskiego pokoju
Choć dla wielu z nas modele językowe wydają się czymś nowym, to wykorzystywane w nich rozwiązania zaprojektowano już kilkadziesiąt lat temu. Najbardziej znanym argumentem dotyczącym "rozumienia" języka naturalnego przez statystyczny model obliczeniowy jest eksperyment myślowy, który w 1980 roku zaproponował amerykański filozof, John Searle.
Argument chińskiego pokoju rozpatruje następującą sytuację: W zamkniętym pomieszczeniu przebywa osoba, która mówi po angielsku, jednak nie zna ani jednego słowa w języku chińskim. W ścianach pokoju znajdują się dwa otwory – wejściowy i wyjściowy. Na zewnątrz znajduje się inny człowiek, płynnie posługujący się mandaryńskim, który przez otwór wejściowy wrzuca do pokoju kartki z tekstem w tym języku. Osoba wewnątrz nie ma pojęcia, co oznaczają poszczególne znaki, jednak dysponuje książką, w której zapisane są adekwatne odpowiedzi na dowolny ciąg symboli w języku chińskim. Przykładowo, jeśli na kartce wejściowej pojawi się napis oznaczający "Jak się masz?" to po odczytaniu właściwej instrukcji człowiek zamknięty w pokoju wyrzuci przez drugi otwór kartkę ze znaczkami układającymi się w odpowiedź "Świetnie! Dziękuję, że pytasz" – odpowiedź będzie całkowicie poprawna, mimo że nasz bohater nie ma zielonego pojęcia, co właśnie napisał.
Czy w tej sytuacji można mówić o "rozumieniu" w kontekście otrzymywanego i generowanego tekstu?
Według Searle'a nie, bo człowiek w pokoju nie wie, o czym toczy się dyskusja. Przestrzega jedynie określonego zestawu zasad, jednak symbole, których używa, nie są dla niego zrozumiałe. Tok rozumowania Searle'a doczekał się bardzo szerokiej dyskusji, która na dobrą sprawę trwa do dziś.
Jeden z argumentów przeciwko przedstawionym wyżej wnioskom wysunęła Margaret Ann Boden, która zauważa, że w miarę generowania kolejnych odpowiedzi człowiek w pokoju może w pewnym momencie zacząć zauważać pewne wzorce i prawidłowości w używaniu znaków. Wtedy przy odpowiednio długim treningu mógłby on nauczyć się w ten sposób podstaw gramatyki, a także stopniowo poszerzać zasób słownictwa na podstawie kontekstu (o ile uda mu się "odgadnąć" przynajmniej jedno słowo, które pociągnie za sobą dalsze "odkrycia").
Przeczytaj: Sztuczna inteligencja w polskich szkołach. Jak działa „Zeszyt.online”?
Czy więc możliwe jest, że odpowiednio duży zbiór danych i dalszy wzrost mocy obliczeniowych może doprowadzić do tego, że algorytm w podobny do człowieka sposób zacznie rozumieć (a może już rozumie) generowany przez siebie tekst? Na to pytanie niestety nie możemy jeszcze odpowiedzieć, a powód jest bardzo prosty – kwestie świadomości, rozumienia i szczegółowego działania ludzkiego mózgu (i jego relacji z umysłem) wciąż nie zostały w pełni poznane.
Na dobrą sprawę dotykamy tu istoty rozróżnienia między tzw. silną i słabą wersją sztucznej inteligencji. Zwolennicy silnej AI uważają, że świadomość może powstać w wyniku czysto fizycznego, niebiologicznego procesu po przekroczeniu trudnej do określenia granicy złożoności i mocy programu. Ci, którzy przychylają się do koncepcji słabej AI, twierdzą, że świadomość albo w ogóle nie jest procesem fizycznym, albo jest tak złożona, że ludziom nigdy nie uda się jej odtworzyć na sztucznych nośnikach.
Jak jest w rzeczywistości? Na odpowiedź przyjdzie nam jeszcze poczekać – według niektórych (np. Elona Muska) może to być mniej niż rok, według innych nie wydarzy się to nigdy, a na pewno nie za życia kogokolwiek z nas.
Źródła: "Cognitive Science: An Introduction to the Study of Mind" (J.Friedenberg, G.Silverman, M. Spivey); ibm.com; techtarget.com; chat.openai.com; arxiv.org; bryk.pl
Marcin Szałaj
Czytaj także:
Anomalie grawitacyjne w Polsce. Jak je wytłumaczyć?
Nauka matematyki korzystna dla mózgu. Dlaczego warto się jej uczyć?
Polacy czytają więcej. Tradycyjne książki wciąż bardziej popularne od e-booków
